云端块存储实现分析
目录
这是一个长期工作,Building…
1 总体介绍
本文尝试从公开资料,分析主流云厂商块存储设备的实现。
云端块存储架构有SAN阵列和分布式块存储两大类。SAN阵列存储其他文章专门阐述,本文描述分布式块存储的典型实现。
从数据分布管理看,有Hash映射和元数据两类方式。从存储引擎看,有原地写和追加写两种方式。从接入方式看,有标准协议和私有化协议。
副本组 :为了保证数据可靠性,一般云盘都是多副本或纠删码存储的。组成多副本或纠删码的一组盘,称为副本组。云盘的一段地址空间会保存到特定的副本组。
1.1 数据分布管理
典型的分布式存储集群有数千块盘。确定云盘写入位置的方式,称为数据分布管理。
1.1.1 Hash分布
Hash分布分两个层面描述。
- 从集群中所有存储介质中,挑选特定数量,组成副本组。目前看到的实现中,只有CEPH 选择了HASH方式,称为CRUSH算法(参见论文)。这里HASH的优势是去除了元数据依赖,物理拓扑无变化时,客户端直接通过Hash函数获取副本组所在的位置;其缺点是物理拓扑变化时,副本位置变化,需要迁移数据;同时,新的副本组开始服务前,要通过 Peering过程就数据副本达成一致,这会导致HangIO;
- 云盘的一段地址空间,映射到特定副本组。腾讯HCBS产品使用此种方式。参见本文对腾讯HCBS的详细描述。
副本组选择上使用Hash存在HangIO、节点不稳定时服务震荡等问题,不适合云服务场景。此处重点描述云盘地址空间到副本组的映射。
为减少元数据规模,同时减少数据复制,一般按照64MB~1GB尺寸切分云盘,每一段称为一个 Segment或Extent。为了IO打的更散,会把多个Segment组合形成SegmentGroup,进一步条带化切分。
Hash方式映射关系简单。但存在组件异常时,慢节点不好规避的问题。IO抖动判定节点异常,会带来较多误判。IO抖动不判定机器异常,会导致明显的性能波动。判定节点异常后,副本组成员发生变化,需要复制数据到新的位置。
腾讯云盘HCBS使用此种方式实现,参见文章: https://cloud.tencent.com/developer/article/1005657
腾讯HCBS虽然存在Master服务器,但明显受CEPH影响太深,对副本组的选择使用一致性 Hash。在单个副本损坏之后,HCBS不是选择一个新的副本和原来的两个副本组成新的副本组,而是要替换整个副本组,这个设计有点匪夷所思。
1.1.2 元数据方式
元数据服务器管理集群内的所有存储介质。根据介质的IO能力,空间使用率,当前吞吐等参数,选择最合适的副本组成副本组,供IO写入。
元数据服务需要提供高可用,并从普通的IO链路上旁路掉,才能保证良好的IO性能。元数据服务一般通过共识算法(PAXOS/RAFT)提供高可用。仔细设计协议和实现,能达成正常IO旁路元数据服务的目的。
Google GFS, Windows Azure Storage, Facebook Tectonic, Alibaba Pangu, 头条,京东,都存在元数据服务管理数据分布。AWS未见到具体架构,但从其专利和E8 Storage的架构来看,也是类似方式。
GFS, WAS, Tectonic 都有相关论文,参见这里。阿里云实现未见到公开的论文,但有一个比较好的资料: https://www.alibabacloud.com/blog/pangu-the-high-performance-distributed-file-system-by-alibaba-cloud_594059
1.2 存储引擎
存储引擎负责数据的持久化。采用追加写模型,还是原地覆盖写模型,是一个非常核心的架构设计。一致性协议、IO链路、故障处理,都会完全不同。
1.2.1 原地覆盖写
云盘切分为固定长度的Segment,对应到单机引擎上的一个或多个文件。对同一个扇区多次写入,总会写入到同一个文件的同一个偏移位置。
原地覆盖写数据位置和大小是固定的,压缩比较难实现。数据压缩之后的大小变化,无法实现原地写压缩数据节省空间。
原地覆盖写的EC一般通过前端加一层Journal实现。尽可能的凑满条带写入,无法凑满的,需要解决写入WriteHole问题。AWS块存储引擎通过Cache/Journal实现的EC。事实上传统阵列都是这种架构。
分布式系统返回TIMEOUT时,IO结果是未决的。允许成功或失败,但不能发生读摆动。在原地写的场景下,部分副本写入成功,部分副本写入失败,读不同副本的结果不同,会发生数据摆动。查询多个副本确认版本号的方式能一定程度解决这个问题,但在伴随节点故障场景下,这里的处理会变得非常晦涩不明。考虑如下场景:
- 三副本R1, R2, R3;
- IO写入,TIMEOUT返回,R1, R2 成功,R3失败;
- 为了缓解IO抖动问题,如果一半以上副本成功,就会返回成功;
- R1所在节点发生故障;
- 读取R2, R3, 现在两个副本上数据不一致,但R1已经丢失,无法判定应该返回R2还是R3;
在原地写场景下,存在更多晦涩难明的一致性问题。
原地覆盖写实现一版初步的,达成80分的产品是比较简单的,可以快速推出产品。并且在小集群环境,资源有限场景,或顺序读多的IO场景下,原地覆盖写还是具备性能优势的。
AWS的块存储是原地写的引擎。从专利和E8架构资料能看出来一些。参见2。
腾讯HCBS、金山云盘,京东ZBS、网易Curve、SmartX,都是这种架构。
华为2019年之前的FusionStorage,字节跳动ByteStore的历史版本,也都是原地写引擎。
1.2.2 追加写
通过增加一层KV映射,在写入成功时,更新数据的位置。失败时,原来的数据不会破坏,依然可以读取。
Azure、阿里云、GCP都是追加写的实现。华为Dorado/FusionStorage,也都采用追加写方式。
追加写在一致性、快照实现上,都具备独特的优势。
1.3 接入方式
- NBD
- Virtio
- NVMe
- iSCSI
- Cinder
1.4 设计分析
- 少量节点故障,IO性能平稳,写入目标位置必须是可以动态映射的;
- 基于元数据进行数据分布管理;
- 基于HASH确定数据位置的方式,在拓扑变化时,会有较多数据迁移;
- 节点数量较多时,追加写的实现,在数据一致性实现,数据复制与前端IO分离上,更具备优势;
- LSM引擎;
- 原地写提升IO稳定性的一种选择是故障时进入M-N写,降低SLA;
- 追加写更好实现EC、压缩等特性;
- 缺点是,追加写后台垃圾回收,会导致IO访问问题;
- 极致性能的产品是一跳的;
- 阿里云PL-X,AWS E8,腾讯极速云盘;
2 AWS
AWS预期没有基于统一分布式文件系统底座实现块存储服务,而是由多种架构合并组成。
这里是AWS EBS产品页面: https://aws.amazon.com/cn/ebs/features/
2.1 From Patent
- https://patents.google.com/patent/US20180183868A1/en?oq=US-20180183868-A1
- https://patentimages.storage.googleapis.com/e6/38/1e/1bf45099e3a6f9/US20180183868A1.pdf
- https://github.com/yygcode/papers/blob/master/patent/aws-ebs-US20180183868A1.pdf
Data storage system with redundant internal networks
Abstract
A data storage system includes a rack, multiple head nodes, multiple data storage sleds, and at least two networking devices. The at least two network devices are configured to implement at least two redundant networks within the data storage system. Also, each of the head nodes is assigned at least two network addresses for communication with the data storage sleds of the data storage system via the at least two networking devices. The data storage sleds each include multiple mass storage devices and a sled controller that is configured to couple with the at least two network switches. In some embodiments, the data storage system further includes redundant power systems within a rack in which the head nodes, the data storage sleds, and the at least two networking devices are mounted.
- https://patents.google.com/patent/US20180181330A1/en?oq=US-20180181330-A1
- https://patentimages.storage.googleapis.com/a6/31/75/b89bceb1d4177b/US20180181330A1.pdf
- https://github.com/yygcode/papers/blob/master/patent/aws-ebs-US20180181330A1.pdf
Data storage system with enforced fencing
Abstract
A data storage system includes multiple head nodes and data storage sleds. The data storage sleds include multiple mass storage devices and a sled controller. Respective ones of the head nodes are configured to obtain credentials for accessing particular portions of the mass storage devices of the data storage sleds. A sled controller of a data storage sled determines whether a head node attempting to perform a write on a mass storage device of a data storage sled that includes the sled controller is presenting with the write request a valid credential for accessing the mass storage devices of the data storage sled. If the credentials are valid, the sled controller causes the write to be performed and if the credentials are invalid, the sled controller returns a message to the head node indicating that it has been fenced off from the mass storage device.
2.2 E8 Storage
2019年7月AWS收购了E8,参见新闻:
- https://www.cnbc.com/2019/07/31/aws-acquires-storage-start-up-e8.html
- https://www.datacenterplanet.com/zh-CN/%E7%A1%AC%E4%BB%B6/aws%E6%94%B6%E8%B4%AD%E4%BB%A5%E8%89%B2%E5%88%97%E5%AD%98%E5%82%A8%E5%90%AF%E5%8A%A8e8/
E8 Client相当于AFA Controller,可实现RAID多写。Client有足够的映射信息,知道IO 应该写到后端某个服务器/盘,不需要后端进行路由。使用电池保护凑满条带写,防止 Write Hole问题。
E8与AWS Nitro集成,可以把E8 Client运行到Nitro Card上。
参考这里:https://wikibon.com/amazon-acquires-blazing-fast-e8-storage-technology/

IO2 Block Express 预期是 E8 实现。E8 延时 40 us,IO2 E2E写岩石在100us以上,有 60us应该耗费在Virtualization,Nitro,Network上了。
2.3 产品分析
AWS EBS持久性比较差,只有5个9。下面是一段介绍描述:
From https://aws.amazon.com/cn/ebs/features/
Amazon EBS 的可用性与持久性 Amazon EBS 卷具有很高的可用性、可靠性和持久性。Amazon EBS 卷的数据可在可用区内多个服务器间进行复制,以防备在任一组件发生故障时丢失数据,无需额外付费。有关更多信息,请参阅 Amazon EC2 和 EBS 服务等级协议。
Amazon EBS 可提供持久性更高的卷 (io2),以实现 99.999% 的持久性和 0.001% 的年度故障率 (AFR),其中故障是指完全或部分丢失卷。例如,如果您让 100000 个 EBS io2 卷运行 1 年,则预计其中只有 1 个 io2 卷会出现故障。这使得 io2 成为业务关键型应用程序(例如 SAP HANA、Oracle、Microsoft SQL Server 和 IBM DB2)的理想之选,将延长这些应用程序的正常运行时间。相比于普通硬盘 2% 左右的 AFR,io2 卷的可靠性提升了 2000 倍。其他所有 Amazon EBS 卷均可提供 99.8%-99.9% 的耐久性,且 AFR 在 0.1%-0.2% 之间。
EBS 还支持快照功能,这是对数据进行时间点备份的好方法。要了解更多有关 Amazon EBS 快照以及如何拍摄卷的时间点备份的信息,请访问此处。
问题在于,假设AWS总共售卖了500万片io2,则一年内可能出现50片坏盘。这个数据还是不小的。估计AWS通过快照恢复(容忍少量丢失)解决了这个问题。
Azure承诺了0%的失效率,阿里云则是11个9,AWS差的有点远。
3 Azure
通过WAS(Windows Azure Storage)与ADLS(Azure Data Lake Store)可以看到Azure 存储架构。
最底层是StreamLayer,实现一个追加写的分布式文件系统。之上PartitionLayer,实现云盘的一段空间。PartitionLayer通过PartitionManager进行负载均衡调度。
Azure Disk最初基于WAS实现了Premium Disk, IO链路经过Blob Cache, Front End, Partition Layer. 后来又优化实现了UltraDisk, 直接从Client->StorageServer->StorageDevices. 参见这里: https://azure.microsoft.com/en-us/blog/azure-ultra-disk-storage-microsoft-s-service-for-your-most-i-o-demanding-workloads/
这个图比较清晰:
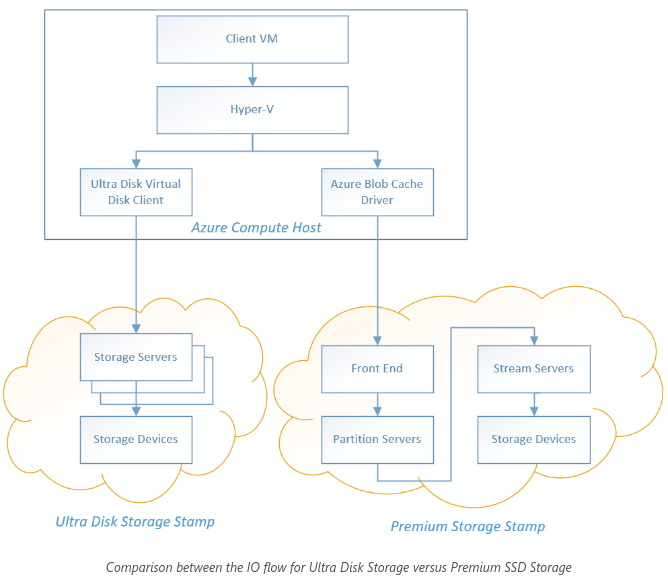
细节参见论文 WAS: https://www.cs.purdue.edu/homes/csjgwang/CloudNativeDB/AzureStorageSOSP11.pdf
或者这里下载:https://github.com/yygcode/papers/blob/master/distributed-system/ds-microsoft-was.pdf
4 Aliyun/阿里云
阿里云在文章(这里,翻译中文在这里)中描述,块存储是实现在分布式文件系统PANGU之上的。
盘古在2021年世界互联网大会获得获得世界互联网领先科技成果奖(这里)。阿里巴巴合伙人蒋江伟领奖时介绍,盘古在四个方面有技术突破:
- 一套存储架构,承载不同应用负载,覆盖低延时、高吞吐、高并发、低成本四个场景;
- 独创分布式数据冗余算法,支持跨数据中心,跨地域的多数据中心容灾策略,数据可靠性达到12个9,可用性高达5个9;
- 自研高性能RDMA网络,HPCC流控算法和新型软硬融合存储引擎,引领云存储进入微妙时代;
- 分布式多级元数据管理,支持数据规模无限扩展;
这四点描述在blili网站也能看到:
From https://www.bilibili.com/read/cv13356345/
自2008年阿里云开始组建盘古团队,到2009年推出第一个版本,再到2013年完成上线单集群 5000台的规模,随后2015年突破了单集群上万台的技术门槛,2017年正式推出盘古2.0并成功支撑了此后每一年的天猫双11全球狂欢节。
而今,盘古2.0作为阿里云CDS的核心支撑底座,具备了四大突出的优势。
一是,通过一套存储架构,支持多个复杂场景,如极低延迟的数据库场景,高吞吐的大数据分析场景,高并发的超算场景,和成本敏感的归档场景。
二是,独创分布式数据冗余算法,支持跨数据中心,跨地域的多AZ容灾策略。数据可靠性达到 12个9,可用性高达百分之99.995。
三是,自研的高性能RDMA存储网络,HPCC流控算法和新型软硬融合存储引擎,引领云存储进入微秒延迟时代。
四是,分布式多级元数据管理,支持数据规模无限扩展。
阿里云提供白皮书描述产品实现与应用。阿里云官网下载地址是这里:https://developer.aliyun.com/topic/download?id=716
Github上这里也可下载:https://github.com/yygcode/papers/blob/master/books/aliyun-storage-whitepaper.pdf
阿里云存储产品及应用白皮书中提到,阿里云所有存储产品基于统一底座盘古:
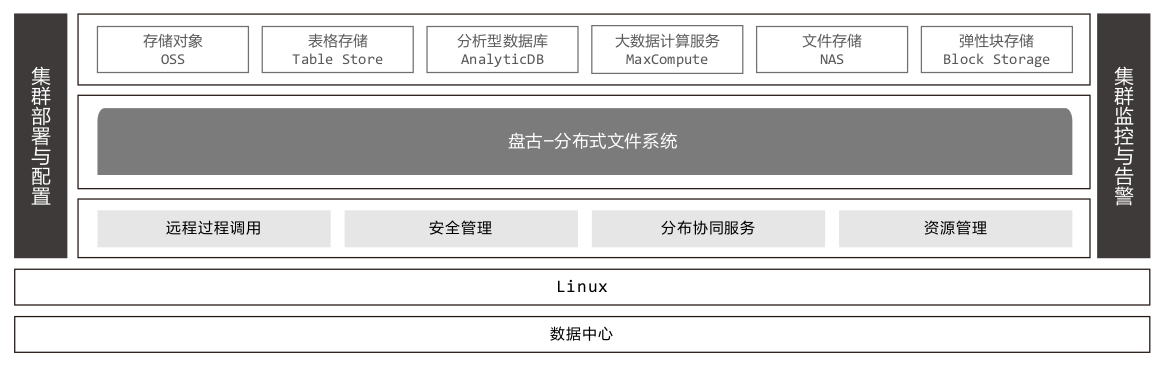
阿里云块存储历史比较久。演进过几代产品。涉及信息保密,不做展开了。
5 Google Cloud
Google Persistent Disk: https://jbd.dev/persistent-disks/
没有找到太多有效资料。推测基于Colossus + LSM Storage Engine实现。
6 Huawei/华为
华为有成熟的存储产品线。典型SAN产品Dorado和OceanStor,分布式存储FusionStorage,在Gartner测试中都是TOP3产品。
华为云基于OpenStack构建。通过Cinder,后端可以接入已有存储产品,并支持打开企业级特性。
华为在硬件研发方向上实力强悍,在硬件卸载方向上,走的比其他几家快。
参见这里文档:https://doc.hcs.huawei.com/zh-cn/usermanual/evs/evs_bms_ug_000012.html
华为Dorado在youtube上有个Deep Dive材料比较深入: https://www.youtube.com/watch?v=WlMdP0NEoLY&t=1749s
7 Tencent/腾讯
腾讯存储产品线比较复杂。TEG团队实现的HCBS,预期是主要售卖产品的架构: https://cloud.tencent.com/developer/article/1005657
联合Intel,推出了写延时60us,读延时40us的极速产品。这里是介绍材料: https://www.intel.cn/content/dam/www/central-libraries/us/en/documents/tencent-cloud-cloud-disk-cbs-cloud-storage.pdf
7.1 CBS 1.0, 2.0, 3.0(HCBS)
- CBS1.0
- 通过iSCSI接入;
- 持久化用已有组件TFS, TSSD, CKV;
- Proxy应该实现iSCSI Target,并转发对应IO到后端持久化组件;
- 预期Master管理云盘创建/删除/加载等;
- CBS2.0
- 实现了一个统一的持久化层Chunk(Cell);Chunk预期是Y型写入;
- Proxy依然是iSCSI Target;
- Master控制和协调整个集群,预期依然是创建/删除/加载等;
- Master如何实现高可用,没有看到材料;
- CBS3.0(HCBS)
- 去掉Proxy,直接从Client写入到Chunk,公开资料中称为CellPair或DiskPair;
- Master记录元数据到ZK,这样可基于AS架构实现高可用;
- 呈现给用户的逻辑卷信息;
- IO路由信息;
- 集群监控:流量,流控,报警,topo管理,故障恢复;
- Driver运行在云主机母机上,向用户呈现块设备,向后端转发IO;
- Driver分为Client和Agent两部分;
- Agent负责逻辑卷和路由信息管理,与Master交互;
- Client处理IO,与后端CellPair交互;
- Agent与Client通过共享内存交互;
- IO路由
- 采用一致性Hash实现;
- \(TabletPairIndex=Hash(DiskId, Lba) % N\)
- 一块盘分为M个Tablet(预期数GB,千量级);
- 一个CellPair内的所有Tablet,组成一系列TabletPair;
- 通过DiskId和Lba,唯一确定TablePairIndex;
- IO下发给TablePair的Primary,由Primary发给两个Slave;
- 故障检测与恢复
- Cell向Master发送心跳,心跳异常则判定故障,TabletPair Slave提升为Primary;
- Cell出现扇区故障,向Master发送自身错误;
- Driver可能向Master上报IO异常;
- 故障时,会提升Slave为Master;
- 故障时,以TabletPair为单位,进行Recovery或Move,无法更换Tablet,而是整个从 srcTabletPair搬到destTabletPair;
- 进行Driver Version 与 TB Version 比较;
- 只有Global/TabletPair Version,没有IO Version,异常场景IO一致性问题比较难处理;
- BinLog + 覆盖写,故障场景下,多副本一致性比较难处理;
- CBS3.0 缺点分析
- 覆盖写实现,分布式场景下数据一致性corner case很多,做正确比较难;
- 缺少IO Version,发生多个节点重启,Failover时,预期存在IO无法定序,以及数据不稳定问题;
- EC/架构是保证可靠性,减小放大比的有效手段,这个架构下不太好实现;
- 总是先写BinLog后写数据,IO放大六倍(三副本写2次);
参考 https://m.e-works.net.cn/articles/article136779.htm
如何实现云硬盘(弹性块存储)系统?
CBS云硬盘起初是依赖腾讯已有的3个分布式系统:TFS提供冷数据存储、TSSD提供热数据存储和CKV提供分布式锁,用这三个分布式系统做简化整合从而产生了CBS 存储后台。
其实最开始CBS是将这3个分布式存储系统拼凑在一起,并在前端封装一个iSCSI的块存储服务,这就是CBS1.0。
但是这个1.0的产品依赖3个庞大的分布式系统,IO链、运维支撑链太长,系统臃肿,可用性极差;所以又把这3个分布式系统在代码层面做了简化整合,从而产生了CBS2.0。
CBS2.0的架构是怎样的?
首先,CBS2.0前端是一个接入集群:
Client,即客户端,让服务器呈现一块硬盘;Proxy,即块设备的后台接入层,前端的云硬盘通过它才能将数据放到云端;Client和Proxy专业名次叫iSCSI initiator和 iSCSI target,就像大家比较熟悉的CS结构一样;Master,集群总控节点,控制和协调整个集群的工作。
同时后端是一个分布式存储集群:
就像经典的分布式存储系统架构,首先接入模块Access提供接入访问服务;存储模块 Chunk负责数据存储;同样它也是一个分布式系统,同样也有一个总控节点,就是 Master。
参考 https://cloud.tencent.com/developer/article/1005657
三个对等的Cell进程组成一组cp(cellpair也称diskpair,Cell进程对应管理一块物理盘disk)结对,以cpid标识每个cp;同时给每个Cell进程分配相同数量M的小表 tb(tablet),以tbid标识每个tb;cp上对等的三个小表组成小表对tp(tabletpair),以tpid标识且全局唯一,tp上的三个tb同样也有主副本之分。如图所示相同色块tb表示属于同一个tp对。
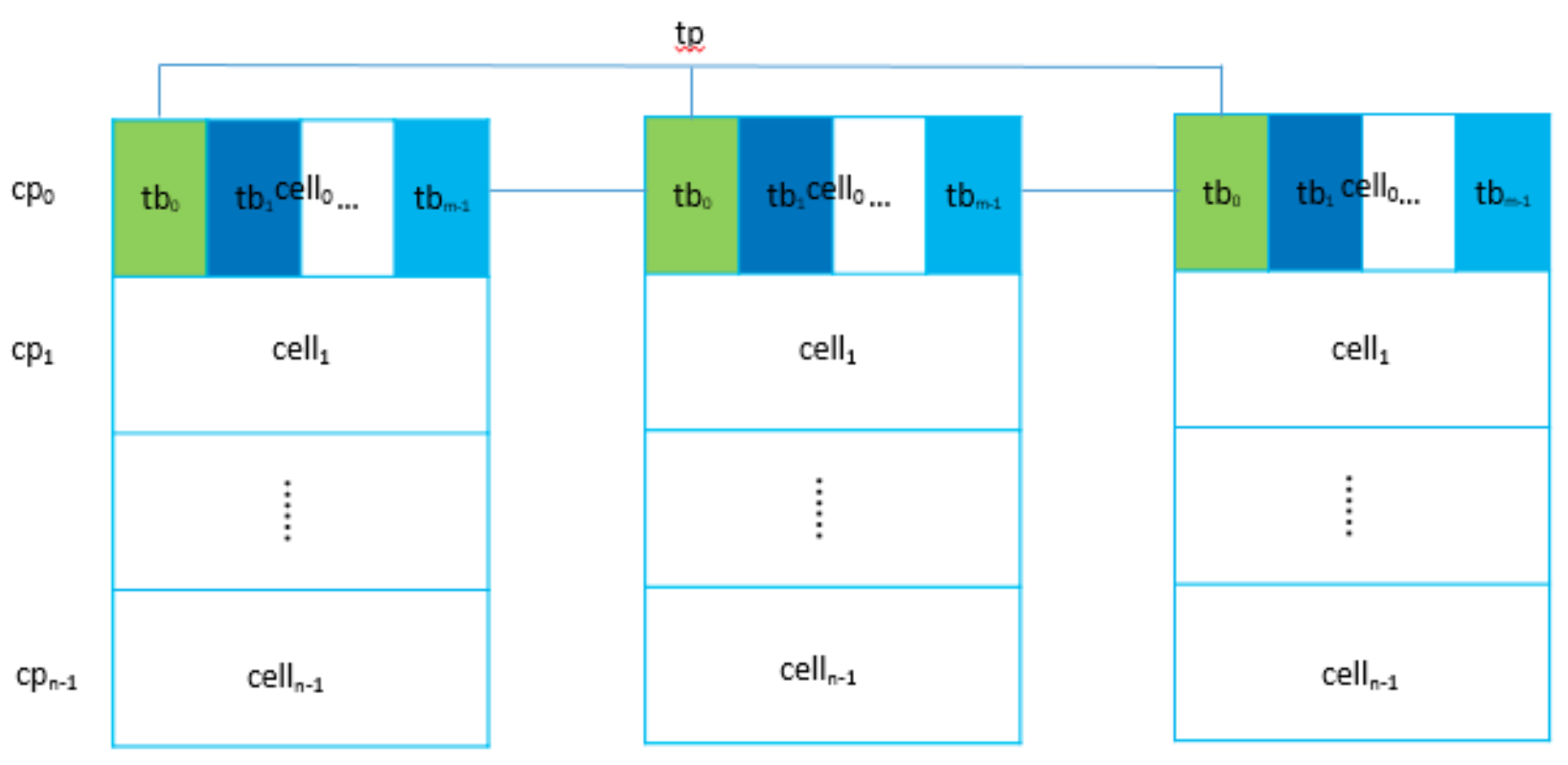
HCBS对于腾讯云分布式存储具有里程碑式意义,其无论是在性能还是成本在云市场都具有很大优势,以HCBS为基础衍生出了许多云产品如NCBS、FCBS、NAS等,HCBS同样支持快照功能。其的优势在于两层架构不仅降低了成本与网络通信,运营也同样变得灵活;同时惰性路由同步策略使得管理数据不需要强一致特性(分布式系统的一大难点在于如何保证各节点数据一致)。扇形多副本写(相比于Driver直接写三副本)不仅降低了Driver端压力,同时也起到了IO封装效果(外部IO转换为存储池内部IO),减少IO 失败概率。但同样也存在不足,从之前描述可以知道HCBS存在结对概念,即副本之间并没有做到完全离散,这使得一个副本故障必须同时换掉其他两个正常副本,代价稍高,这是后续优化的重点。
如同总体介绍中描述的,都已经具备元数据了,稍微增加一点元数据就能在维持现有2副本的前提下,复制一份数据,重回三副本,。HCBS选择了另外挑选一个CellPair复制三份数据,这个实现有点摸不着逻辑。
7.2 极速云盘
8 Smartx
8.1 存储引擎
SmartX在专有云/超融合领域市场反馈比较好。在看到的资料里,SmartX在分析KernelSpace, LSM的缺点后,提出了自己Journal+PerformanceTier/CapacityTier的框图。SmartX明确表示自己不是AppendOnly架构。推测这里应该是Journal SSD + HDD分层实现。SSD作为 Journal使用,数据Dump到HDD后即可回收。HDD是原地写。这种架构下,用SSD再实现一个加速缓存是常见策略。
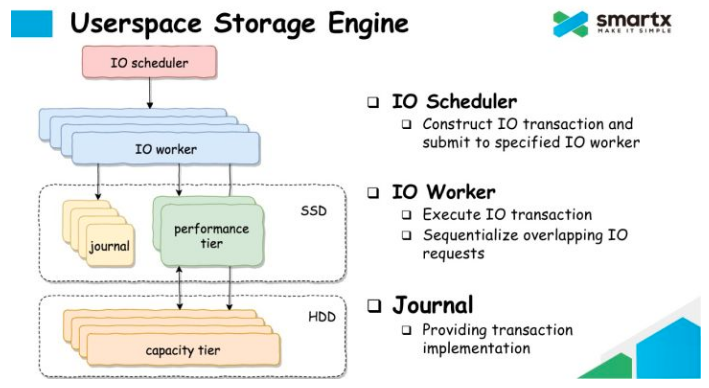
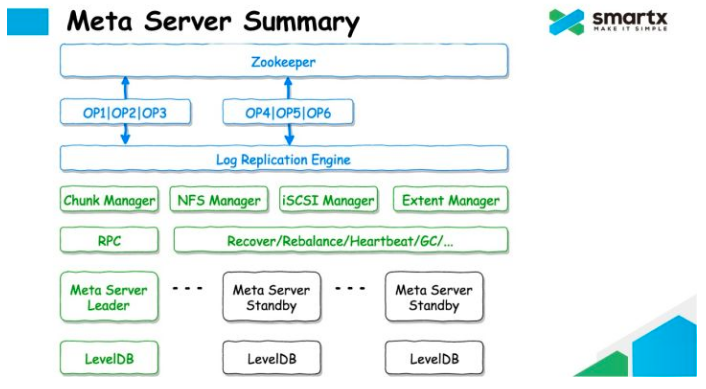
8.2 元数据服务
元数据服务使用LevelDB/RocksDB持久化元数据。使用ZooKeeper同步修改日志。
元数据服务包含了ChunkManager, NFS Manager, iSCSI Manager, Extent Manager。没有看到资料表示Chunk和Extent的相互关系。
9 References
- 腾讯HCBS
- https://cloud.tencent.com/developer/article/1005657
- 金山 KingStorage EBS
- SmartX ZBS
- https://www.smartx.com/blog/2018/09/zbs-intro-storage-engine/
- SmartX ZBS 存储引擎篇
- https://zhuanlan.zhihu.com/p/44250377
- SmartX ZBS 元数据篇
- https://zhuanlan.zhihu.com/p/36138609
- Google Colossus
- Colossus under the hood: a peek into Google’s scalable storage system https://cloud.google.com/blog/products/storage-data-transfer/a-peek-behind-colossus-googles-file-system